
User Defined Functions (UDFs) allow you to easily build logic to process columns in Spark but often can be inefficient, especially when written in Python. Scala UDFs are significantly faster than Python UDFs. As in orders of magnitude faster. Recently worked with someone that needed a UDF to process a few hundred GB of data. When switching from a Python UDF to prebuilt Scala UDF processing time went from 8 hours and giving up to around 15 minutes. Finding how to do this though was a challenge, so I want to document the process for others.

Had a recent issue come up where a customer was trying to use the Python Library twobitreader in a UDF to pull out some genetic information for individual genes. Think of it like being able to look up a range of characters from a file and output them as a string. The problem they were running into...
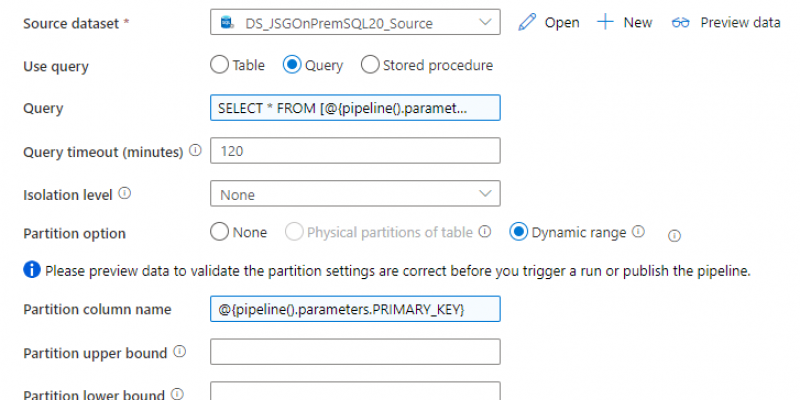
This uses a relatively standard process of a query to look up all the tables in a database, iterating over them, and passing the tables via parameters to a copy operation. The primary benefit of this setup is it allows you to use dynamic partitioning where possible and uses very high concurrency.